Are you new to the topic of document data extraction? If so, you’ve come to the perfect spot. Today, you’ll delve into the fundamentals of extracting data from documents. We’ll also show you how to automate this process and deal with specific document types so you can apply it in your business.
Because, hey, every business deals with docs. No matter if you extract data from several invoices or hundreds of different doc types a month that come from a variety of sources. It’s always an upsetting chore. But it doesn’t have to be that frustrating.
Modern technologies automate the process, so manual data extraction can become a thing of the past. Let’s explore the basics and finish with practical examples and document types from various industries.
What is Document Data Extraction?
Data extraction is a broad field that covers pulling data from one source to another. Businesses usually do it to further process data or store them digitally. Say, you’d like to pull your spreadsheet data to an accounting tool to make payments — that’s where data extraction is necessary.
There is a niche in data extraction called document data extraction.
It’s the process of automated extraction of specific data fields from unstructured (e.g., contracts) or semi-structured documents (e.g., invoices). You can pull data both from digital documents and traditional print ones. With physical docs, you’ll have to digitize them first.
Intelligent document data extraction is an automated process that’s based on the following:
- Optical character recognition (OCR) converts scanned or printed text into machine-readable data by analyzing the image of the doc and recognizing the characters, words, and sentences along with other objects like logotypes, handwritten signatures, and more
- Machine learning (ML) algorithms that are trained on labeled data to recognize patterns and extract specific information from documents
Natural language processing (NLP) techniques enable structured data extraction from unstructured text. For example, pulling critical information from a contract or identifying specific data from a customer feedback form.
Those advanced technologies help businesses in various industries identify and extract specific fields from any document type.
Imagine data from that pile of documents sitting on your table can be easily pulled out of those docs and exported in a CVS or other file type further. If you want to introduce automation in your business and automate data entry, this is something for you.
What Does Automated Data Extraction Process Look Like?
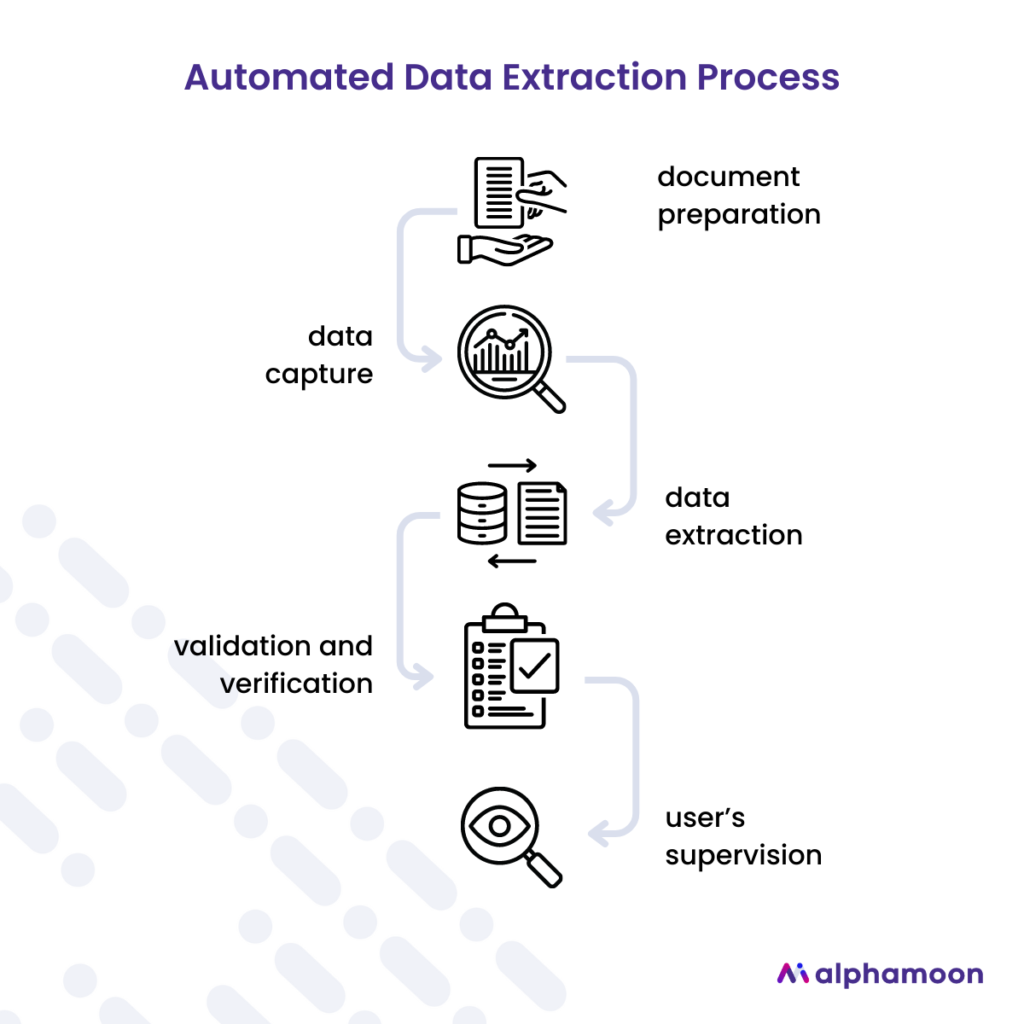
Document data extraction is a five-step process:
- Document preparation: Basically, this step involves converting physical documents into digital format (e.g., a PDF file) through scanning or uploading electronic files.
- Data capture: Once the documents are digitized, e.g., Alphamoon’s AI-based OCR converts images into machine-readable text. Thanks to OCR, the system recognizes and identifies the characters and text of a document and extracts the required data.
- Data extraction: After the OCR, NLP algorithms are applied to analyze the textual content and identify specific data points. These algorithms can understand the text’s context, structure, and meaning to extract the necessary information.
- Validation and verification: The extracted data is validated against predefined rules and algorithms to ensure accuracy. This step helps identify any errors or inconsistencies in the extracted data.
- User supervision: After document data extraction, the user can check the correctness of extracted data. In Alphamoon Workspace, extracted fields can be either edited or words can be reassigned.
But there is more. Data extraction is just one puzzle piece in the bigger process. Eventually, you’d like to work with the extracted data, right? In this case, you have a couple of options.
- Export extracted data from documents to another tool.
You can export:
- A single document by accessing it on the right-hand side (by pressing on three dots and exporting)
- The whole collection of documents by accessing it on the left-hand side (by ticking the box and pressing the export icon)
As for formats, the exports are available in CVS, JSON, or Excel formats. Later, you can upload your document data to a preferred tool.

- Create an automated workflow using Zapier and its extensive app directory.
You have multiple options, but let’s start with two examples.
Connect Gmail with Workspace through Zapier
Say you’d like to extract information from documents sent to your Gmail. You can set up the following automation:

When you get an email with an attachment (e.g., invoice), it triggers an activity action: creating a new file processing in Alphamoon.
Thanks to this automation, you won’t miss any attached documents sent via email, and you’ll automatically pull data from them.
If you’re interested in that type of workflow, stay tuned as we’re working on adding document classification to Workspace soon!
Connect Google Sheets with Workspace through Zapier
Another way to automate business document processing is to connect Alphamoon Workspace with Google Sheets. By setting a trigger ‘New process collection appears,’ update spreadsheet row(s).

Thanks to this, you’ll be automatically exporting results to Google Sheets. You have hundreds of options for how to set up your workflows. The specific use case depends on your current stack and needs.
Why is Document Data Extraction Important for Your Business?
It is easy to manually pull data from a couple of documents monthly. But businesses process tons of documents in different formats, languages, and types. Because of that, manual processing is no longer practical.
You know how it is, right? A pile of documents is waiting on your desk (or in a folder on your desktop), and there are hundreds of more burning tasks to complete.
Because your business processes large amounts of various documents, extracting relevant information is essential. Still wondering what are the exact benefits of automating data extraction from documents? There you have it.
8 Benefits of Document Data Extraction You Should Be Aware of
If you’re an SMB starting its journey with automation, document data extraction is the right place to begin. It’s because adding automation to this process can:
- Save time and costs: Manual data entry is a tedious task that’s time-consuming and prone to errors. Document data extraction is a more automated process where you can quickly pull data from any type of document. As a result, you save time and money and can focus on more valuable tasks
- Improve customer service: Faster data extraction can enhance customer service as you’ll provide more timely and accurate information, often in real-time
- Improve efficiency: If you have a pile of different document types, the manual process of analyzing every single document isn’t efficient. Automating data extraction allows your business to process more documents in less time
- Unlock scalability: Thanks to more efficient data extraction, you can handle large volumes of documents and scale your business operations
- Enhance accuracy: Human eye can be fallible when many documents are similar documents and contain a lot of numerical information. Extracting data from docs automatically minimizes the risk of inaccuracies, ensuring higher data accuracy and integrity
- Lead to actionable insights: It takes time to spot patterns or see trends by browsing through a pile of physical documents one-by-one. But if you have all the data together because you’ve just extracted it from 100 docs? That’s a different story. Now, you can play with this data, analyze it, or sort by total amount and other factors
- Speed up the strategic decision-making process: With quicker access to extracted data, your organization can make faster and more informed decisions
- Guarantee more compliance and data security: Data extraction can enforce consistency and adherence to predefined rules, improving regulatory compliance. And when it comes to data security, centralized digital data is easier to secure and manage compared to physical documents
While there are many benefits, the tech world isn’t ideal, and that’s also the case with document data extraction.
Challenges of Document Data Extraction and How to Address Them
From handwritten forms, stained invoices to colorful passport backgrounds, extracting relevant data can be tricky sometimes. Let’s see the most common challenges when pulling data from documents and how to handle those issues.
1. Poor Data Quality

Ok, someone just sent you an invoice that looks somewhere like this. Clearly, the afternoon coffee break ended in a rather unexpected way showing that documents and coffee aren’t the best pals.
But jokes aside, dealing with such documents ain’t fun.
Blurry text, creased paper, and stains on docs are problematic. Not to mention those issues can hinder the extraction process, leading to errors and unreliable results. And this, in turn, can cost you a lot of stress that could be prevented thanks to document automation.
Modern optical character recognition (OCR) technology (like the one Alphamoon Workspace is employed with) can handle those obstacles. OCR algorithms can analyze and interpret text from various document types, even those with lower quality.
And one more thing, modern data extraction solutions have a supervision part where you, as a user, can check the accuracy of data extraction. Especially when docs come with low quality or stains — keeping a human in the loop gives you loads of control.
2. Variability in Document Formats

You already know well that even a simple document as an invoice can come in various shapes and sizes.
Unique structure, layout, and formatting can challenge automated data extraction tools. It’s especially true about traditional machine learning models. They need diverse training data to identify and extract information from even unique docs.
But there is also innovative zero-shot learning where models don’t need training data to extract data even from document types it has never seen before. Yeah, that’s right — you can pull data from even the quirkiest invoice you’ve ever seen with zero-shot.
3. Complex Documents with Noisy background
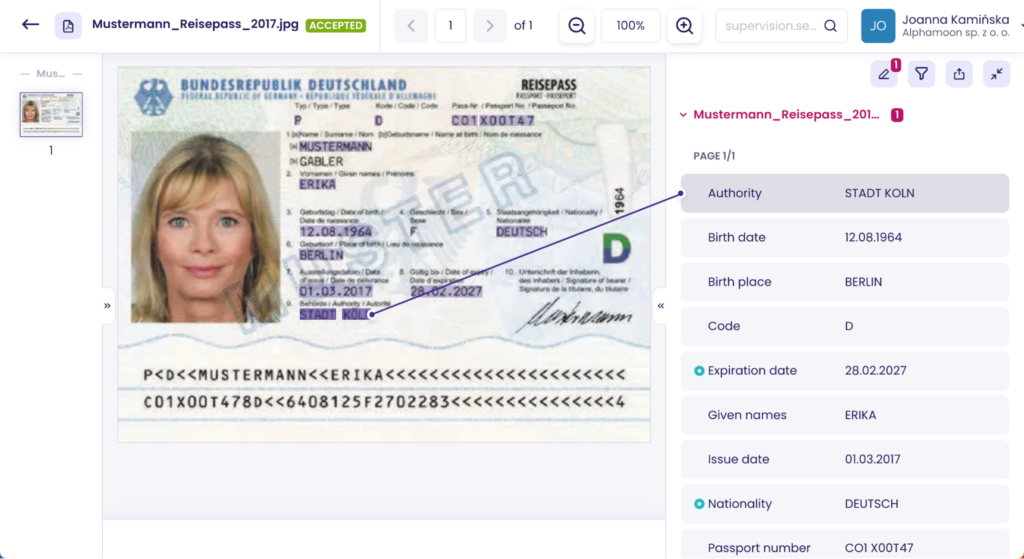
Identification docs always have complex backgrounds. This might be the hardest challenge of data extraction from documents. Gradients, different colors, and printed shapes give extraction tools a hard time.
But as you can see, Alphamoon’s Workspace engine handled data extraction despite the noisy background of this passport. If you work in banking, this is crucial if you’d like to:
- Simplify identity verification
- Improve customer onboarding
- Boost the KYC process
Want to see more data extraction examples? You’ll find them in the next section.
Document Data Extraction: 5 Use Cases in Finance, Healthcare, Insurance, Logistics, and E-commerce
In this section, you’ll get a lot of practical examples of how to extract data from documents in various fields. Let’s jump right into it.
Document Data Extraction in Finance
Automated document data extraction can help you speed things up, reduce the number of errors and improve the whole process. You can use automation to deal with invoices, processing, expense management, and contract analysis.
We uploaded this document and wanted to extract the following information:
- Accounts payable
- Inventories
- Term debt
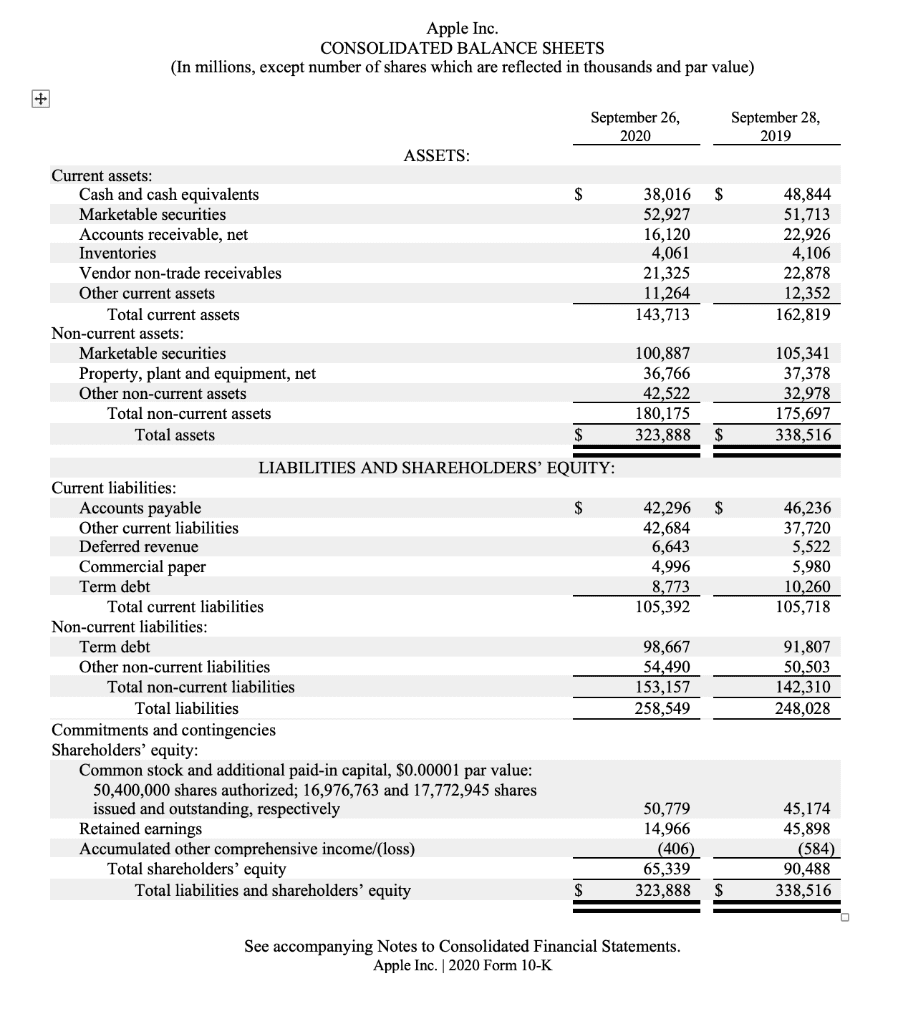
As there was no ‘net income’ on this financial statement, the tool showed this in the ‘missing field’ section.
Document Data Extraction in Healthcare
Suppose you’re working for a healthcare organization. In that case, you deal with medical records, insurance documents, and information from social security cards.
Thanks to healthcare docs automation, you can:
- Improve the administrative part of your job
- Enhance patient care (because you’ll always have real-time data)
- Speed up document processing and face fewer errors
Document data extraction from healthcare docs can also improve interoperability between healthcare systems. It’s because you can always send the extracted data via Zapier or API integration.
Look at how data extraction worked for two documents: a social security card and a personal health record. We’ll show you the step-by-step process so you will know how to do it yourself with the documents you have.

We created a ‘custom’ process in Alphamoon Workspace in both cases.
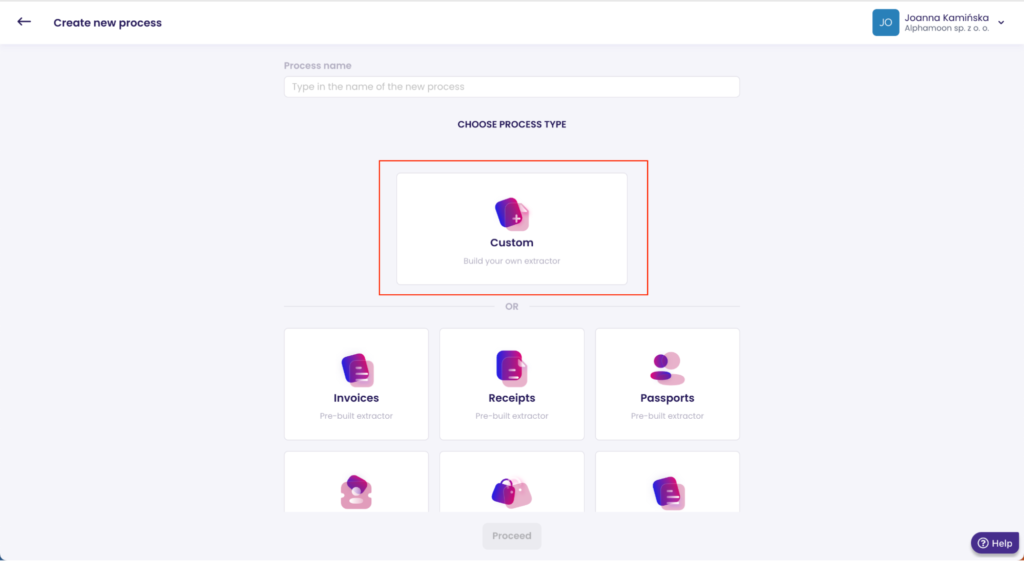
Then, we added all the fields we’d like to extract data from, such as name, surname, gender, patient identifier, insurance carrier, and insurance plan.
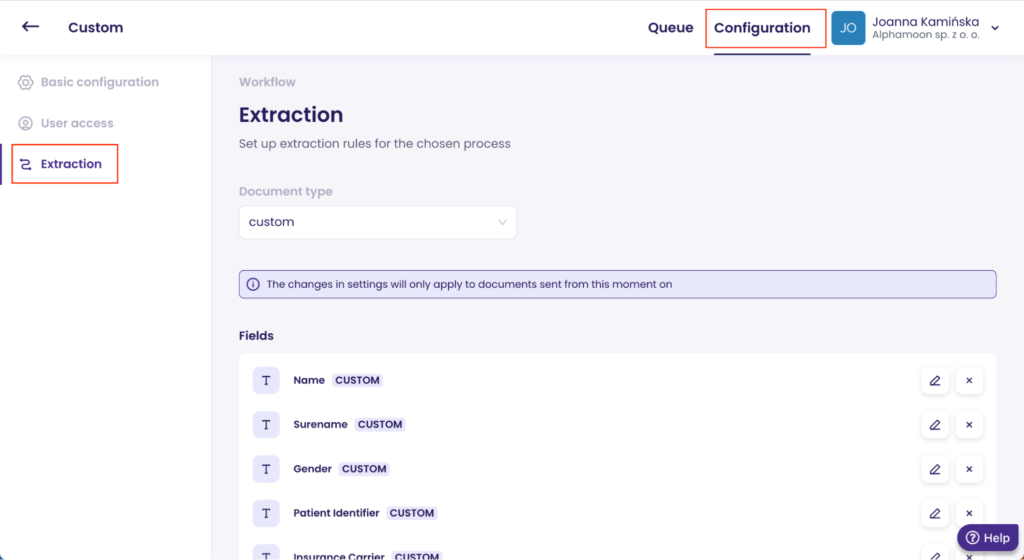
Then, from the configuration window (right top corner), we went to ‘Queue’ and uploaded two documents:
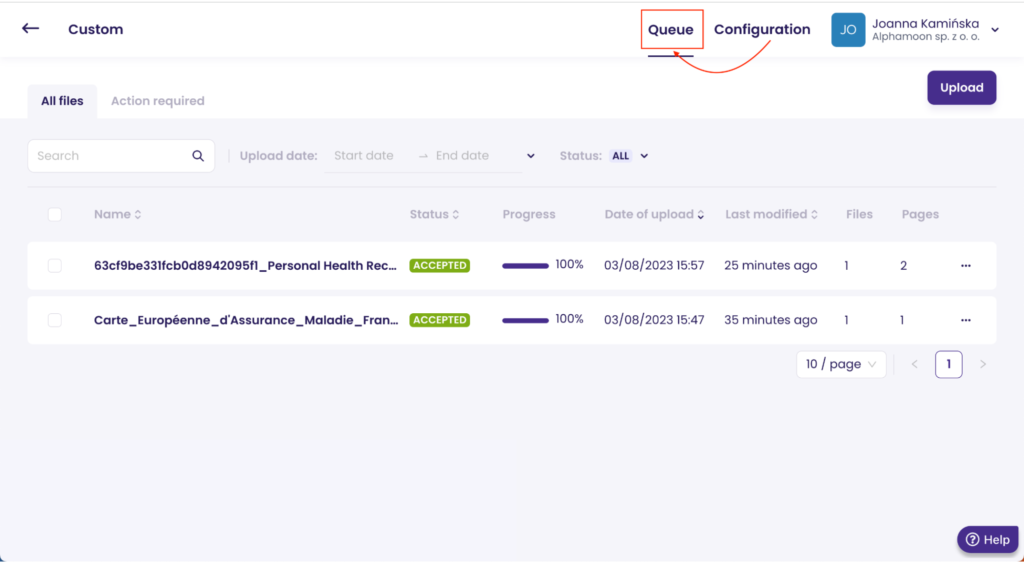
And here it is, the outcome of this data extraction for social security card and healthcare records:

If you see a yellow dot close to the extraction field, it means the field was edited. The supervision part gives you complete control over data extraction and its correctness.
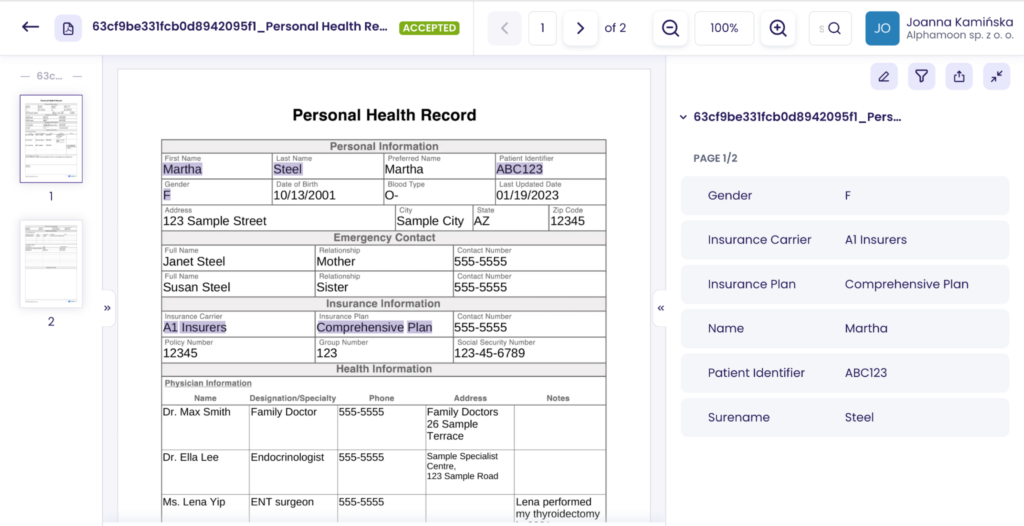
In the case of a personal health record, all the data were extracted correctly, meaning there is 100% data extraction accuracy.
Document Data Extraction in Insurance
Suppose you’re working in the insurance sector. In that case, you know how heavily it depends on moving data from one source to another.
Your daily chores include claims processing, policy management, and risk assessment. Imagine you put some of this processing on autopilot. In that case, you can speed up claims settlement, reduce manual errors and improve the accuracy of underwriting processes.
We don’t advise putting everything on autopilot as with document data extraction; having a human in the loop is always good. Thanks to the supervision option, you’ll check the document and see if the data were extracted correctly.
Take a look at the practical example of data extraction from the insurance policy:

As you see, all the data were correctly pulled from this insurance policy. If you want to export just this document data, go to the right side of the UI and press the export button.
By exporting all your insurance policy data, you do many things, from transferring it for storage or using it in analysis.
Document Data Extraction in Logistics
Suppose you feel overwhelmed with manual administrative work like transferring data from one system to another or manually updating shipping information. In that case, document data extraction is a thing for you.
It’s because it helps you speed up data extraction and move this data to other places while decreasing the chances of human error or bottlenecks in the process.
And as you know, the shipping information must always be correct. Perfect if it’s also up-to-date so customers know when they’ll get their deliveries.
Let’s extract relevant information from logistics documents such as a bill of lading and delivery receipt in Alphamoon Workspace.
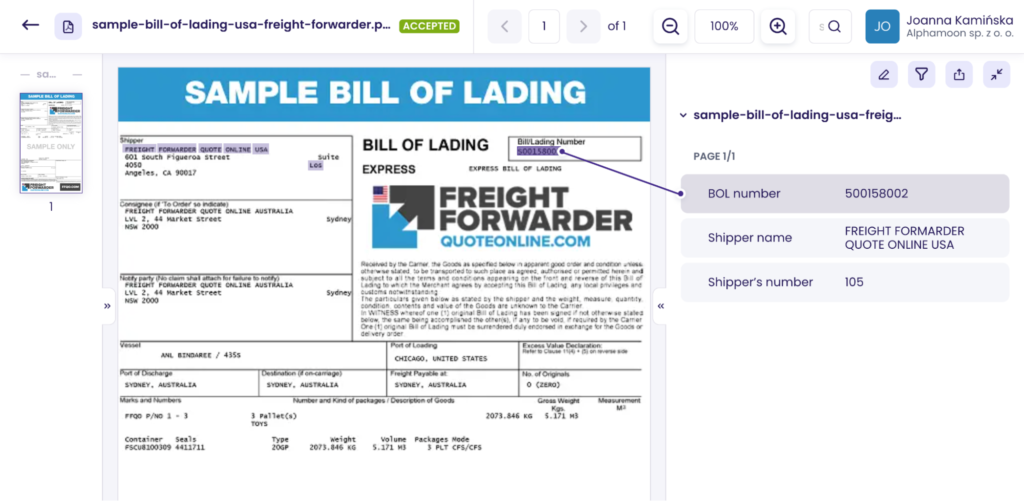

There are many more options, and you can extract data from any possible document in logistics. Extracting data from docs automatically leads to improved accuracy of orders and enhanced tracking and traceability.
In addition, if you’re a courier working in logistics, you can pull data from any document in seconds. You just need to scan the document, send it to a specific folder via your phone, and Alphamoon does the real-time extraction of data about a parcel.
Automated document data extraction in logistics also helps integrate your systems and improves general efficiency and customer satisfaction.
Document Data Extraction in E-commerce
You know the deal with document volumes if you work in the e-commerce industry. Invoices, receipts, product labels, and packing slips are piling up. And chances are, you need data from some (or most) of those docs.
As you know, manually rewriting or copy-pasting data from those docs is a burden. But there is a faster and better way to go. Automated data extraction from transactional docs and transferring it to another system or storage will help you process more docs faster with fewer errors.
Because of this, you’ll stay in control over ordering fulfillments, managing inventory, or processing customer service docs.
Let’s see a couple of examples.
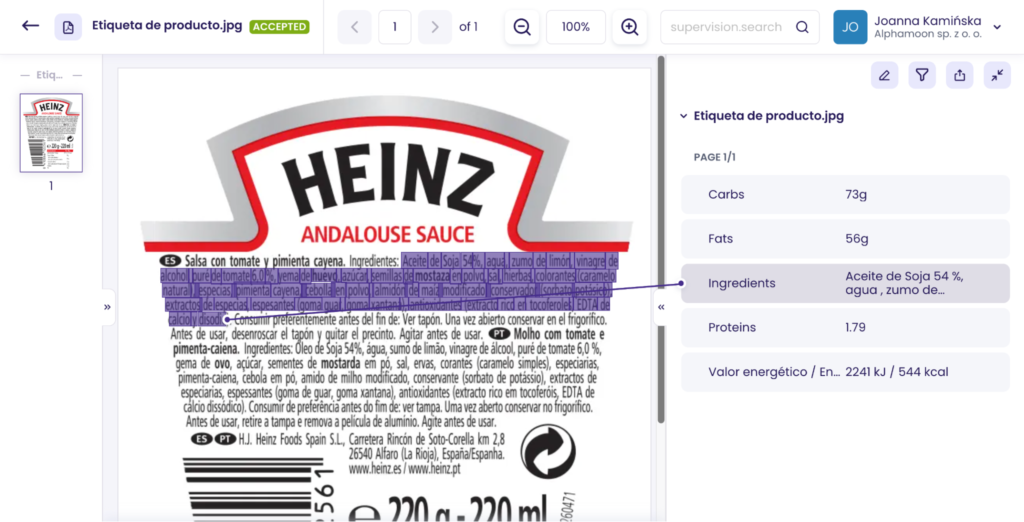
Say you have hundreds of products for your e-commerce store that you received from the distributor or manufacturer.
And if you’re selling them online, you must populate your landing pages with product data. And here, extracting all relevant information from product labels comes in. You’ll transfer properties like ingredients, barcodes, and nutritional values to your pages.
With automated data extraction from product labels, it will be a matter of minutes to check the correctness of the extraction, export the data in various file formats and upload them into your product management system (PIM) or place them straight in an online product listing.
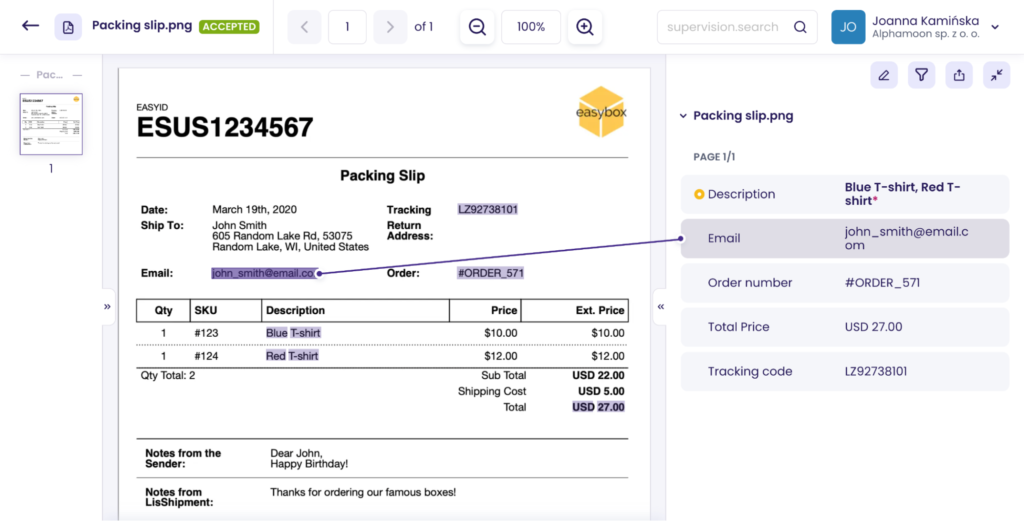
The same goes for any other e-commerce document. You can also quickly process docs and pull data from packing slips, gift vouchers, complaint forms, or popular docs like invoices or receipts.
Improve Your Key Workflows with Intelligent Document Processing
No matter which industry you represent, documents are part of your job for sure. So is data extraction and all the actions around that topic.
By automating the process of extracting valuable information from various types of documents, your business:
- Saves time on pulling every single data field manually
- Reduces human errors while rewriting data from physical docs to digital files or copy-pasting digital docs to other spaces
- Improves overall efficiency while maintaining high accuracy of extracted fields from any document
While many AI-based OCR and data extraction tools can handle just typical docs like invoices or purchase orders, that’s not true for Alphamoon Workspace.
Our tool is equipped with zero-shot learning that can handle any document type you want, giving you endless possibilities for data extraction fields. Everything with at least 80% of extraction accuracy.
So, will you say “bye” to manual data extraction from documents? At least try it — the first 50 docs you process are on us!


