Finding the best software to help you with data extraction is not easy. Most companies that offer data extraction tools promise high performance, however it’s difficult to compare them. That’s why Alphamoon team has conducted a comparison analysis of our data extraction tool with products offered by Microsoft, Google, ABBYY, and Kofax. Alphamoon has topped the competition by delivering accuracy level of 82.5% for a set of outdated invoices and 98% for a set of modern, commonly used invoices.
Some say that only two things are certain in life – taxes and death. Consider adding one more thing to the mix – documents.
Why?
Because every company, organization, or individual generates documents.
From letters sent in bottles that drifted across the seas to invoices provided to sellers or contracts signed between employers and employees.
It wouldn’t be an over-exaggeration to say that individuals and companies generate thousands of documents every second around the world.
Let’s focus on the business perspective. The more documents are created in a company the more complex processes are established to classify them. Handling paperwork manually can be quite a nightmare, hence more companies turn to solutions that help with document automation. How can you choose the best software though?
In this article, we provide with an answer. On top of that, we’ll also explain:
- what is data extraction and information extraction
- how companies evaluate their data extraction software & how to compare them
- what are the challenges in fair measurements of such tools
Furthermore, you can read a detailed comparison of Alphamoon, Kofax, ABBYY, Google, and Microsoft that proves Alphamoon’s leading technology in the field of invoice processing and receipts processing.
If you’re already sure that this data capture and extraction technology is for you, click below and talk to our team.

If not, let’s start with a bit of theory.
What is data extraction?
According to Wikipedia, Data extraction is the act or process of retrieving data out of data sources for further data processing or data storage.
In terms of document automation though, we usually talk about information extraction which is a process of capturing specific pieces of information from semi-structured or unstructured, machine-readable documents, i.e. names, dates, addresses, or any other field. Types of such information can vary – based on visual or textual context, as well as the layout of the document. Information extraction provides essential input for further data processing.

Usually, there are two main components in a given extraction pipeline – OCR and Entity/Data extraction.
OCR refers to a technology that reads documents and converts them into editable texts. Any pdf or image file is firstly scanned and then goes through extraction – the second part of the pipeline. Modern OCR tools are supported by artificial intelligence, which helps with less structured or damaged documents.
Okay, so is finding relevant pieces of information as hard as finding Wally on the beach?

Thankfully, it’s not.
However, considering the various templates used by even a single enterprise, data extraction isn’t as easy as you would think.
Now, multiply dozens of templates and contractors by hundreds of invoices.
You end up with a complex database, consisting of an overwhelming amount of paperwork to be done. If something goes south, and you need to manually flick through all documents – you’re in for a ride to hell.
Take a look at the example of an invoice below, from a company we called EAT&MEET Restaurant.

Data extraction can help EAT&MEET Restaurant process any invoice from Shells & Bells much quicker. Data extraction software finds the relevant information, such as:
- invoice number – H234Kfll-345
- contractor’s address – 8758 Heather Street Milford, DE 19963
- and amount to be paid – $250.50
Without automation, all this data would need to be manually processed.
If EAT&MEET used OCR technology, then the process would end with the conversion of image into text. The restaurant manager who receives the documents, pays the contractors and so on, would still need to complete a fair share of this process manually – copy the address, the invoice number, and the amount to be paid to relevant applications.
Still a nightmare, right?
That’s why simple rule-based OCR software is not enough in most cases. For bigger companies, the goal is automate invoice processing as a whole process.
What matters to OCR is whether the information is a text, a position or a visual appearance to be read. OCR transforms documents (scans, photos) into editable text, but provided that the template can be read.
If Shells & Bells changes its invoices template, then the OCR tool would require an update of the template too.
That is also why the market is shifting to AI-based OCR, a component of Intelligent Document Processing.
While traditional OCR software is built on the rule-based model, IDP combines machine learning, AI, and natural language processing (NLP) to provide high accuracy of data extraction and classify the extracted information so that it can be further streamlined and utilized.
Hence, if your company processes thousands of documents every month, AI-based document automation seems like a natural choice for improving your workflows.
Once you settle on taking the step toward automation, you need to find the best data extraction tool that will help you process documents and extract valuable data from them.
Read on to find out about the results of the comparison of the leading providers – Microsoft, Google, ABBYY, and Kofax – with Alphamoon’s platform.
Best data extraction tools – comparison assumptions and details
How to compare document automation tools without jeopardizing the legitimacy of the results then?
Well, the way most companies evaluate the performance of different extraction tools is by testing their accuracy on some document sample that wasn’t previously presented to the vendors.
In order to compute the exact accuracy of each tool, the document sample has to be manually labeled (annotated) first. It means that a person needs to provide a complete set of correct answers/fields for each document, which is also called a ground truth.
The accuracy is then calculated by comparing the ground truth with the results delivered by each of the tool. AI-based platforms that implement Intelligent Document Processing use this ground truth to learn and improve their performance – contrary to the so-called legacy OCR software.
Data extraction tools comparison – Evaluation setup
Before we describe the results, let’s discuss the main metrics we used in the test.
The main criterion to look at while comparing different platforms is the accuracy of data extraction.
Accuracy is the percentage of correctly extracted data from all test examples. The field is accurately extracted only if the software reads the data correctly and the data extractor – that is you or your employee – recognizes the field type and marks it as correctly extracted.
Accuracy is usually proportional to the time savings that the user gets. By calculating the average time spent on a single invoice – manual data extraction and further processing – you can easily see the time saved when the same invoice might – depending on the learning process of the platform – take less than a minute to process. All it requires is the verification step.
The second metric often used when comparing data extraction products is Straight-Through Processing.
Straight-Through Processing (STP) is a metric used to determine the level of automation. It is the percentage of documents, where all fields were extracted correctly.
While data extraction accuracy tells you the percentage of correctly extracted pieces of information from the set, Straight-Through Processing takes the macro-perspective and establishes a percentage of all correctly processed documents within the dataset.
Let’s look at that difference in more detail.
There are many other technical criteria that we could consider in such a comparison. These may include:
- the number and types of data fields that are available to extract,
- time of processing,
- scalability to huge document volumes and robustness to demand peaks,
- deployment options and integration capabilities,
- extraction capabilities beyond pure text (e.g. extracting tables, handwriting, graphical objects),
- additional validation and post-processing capabilities,
- intuitive UI.
However, for simplicity, this comparison is based on the two main evaluation metrics.
Challenges in comparing data extraction tools
Fair and transparent comparison of information extraction engines is difficult due to several reasons.
The list of extracted fields usually differs for different providers. Therefore, the accuracy comparison must be limited to only a subset of common fields, which shows only a partial picture of each provider’s performance.
Furthermore, most vendors do not provide public access to their platforms so data isn’t easy to get. Since they’re not cloud-based, open solutions, testing the capability of each tool isn’t simple.
Perhaps the biggest challenge is, however, the lack of publicly available and well-crafted datasets for extracting information from common document types such as invoices or receipts. Since invoices and receipts contain sensitive data concerning transactions, there are very few datasets that can be used to test the accuracy.
The above prompts some providers to utilize their own datasets to improve the capabilities of their tools, thus leading to a highly biased result in any accuracy test. To keep our own comparison fair, we have used two publicly available datasets – one for receipts and one for invoices.
Data extraction from invoices – Comparison of Alphamoon, ABBYY, Google, Microsoft, and Kofax
In order to test the accuracy and data extraction capabilities of Alphamoon’s platform we have compared it to the following tools:
- ABBYY FlexiCapture for Invoices Cloud
- Google Document AI Invoice Parser
- Microsoft Azure Form Recognizer invoice model
- Kofax AP Essentials for Invoice Automation
As we have explained, in order to provide the highest possible neutrality of the test, the experiment was conducted based on a publicly available dataset – The RVL-CDIP Dataset.
The dataset consists of various types of documents – letters, memos, emails, governmental forms, handwritten notes, invoices, advertisements, etc. – from which we have chosen a sample set of 188 invoices.
Since the documents were not prepared for evaluating information extraction tasks, Alphamoon team annotated them manually to prepare the ground truth. We have chosen 7 fields for the data extraction test:
- invoice number
- invoice date
- total amount
- seller name
- seller address
- buyer name
- buyer address
A bunch of invoices used for this comparison test is added below.

Even a quick glance at those four examples should hint at the outdated character of the documents.
Such a challenge – a dataset with a plethora of low-quality document scans – wouldn’t naturally occur today. Modern templates of invoices are of much better quality and structure, and therefore the results of this test would yield higher results for all the products we tested.
The results of the comparison clearly indicated that Alphamoon achieved the highest accuracy score among all tested platforms.
Our findings:
- Alphamoon’s accuracy score has reached 82.5% meaning that the vast majority of all the 7 defined fields were correctly extracted. In other words, less than every fifth field would require correction.
- Microsoft Azure Form Recognizer invoice model achieved a 75.4% of accuracy. Every fourth field would require human correction in the case of Microsoft’s tool.
- The two tools were followed by Google Document AI Invoice Parser’s 68.1%, ABBYY FlexiCapture for Invoices Cloud’s 51,9%, and Kofax AP Essentials for Invoice Automation’s 15.8%.

And now to the nitty-gritty details.
The accuracy was evaluated using the F-score measure, using the following formula:
F1=TP/TP+0.5(FP+FN)
where:
TP = True Positives
FP = False Positives
FN = False Negatives
The reason for choosing F-score is that it is very good at approximating the percentage of time savings provided by the tool.
To be even more specific, in the majority of situations when the data extraction tool makes a mistake, it only recognizes some other piece of information as the one that was intended. In such a case the tool makes two mistakes – one false positive (extracted data is not the correct one) and one false negative (the tool did not capture the required data). Nonetheless, that still requires only one correction to amend the error. F-score captures that nuance by having the 0.5 factor in the denominator of our formula.
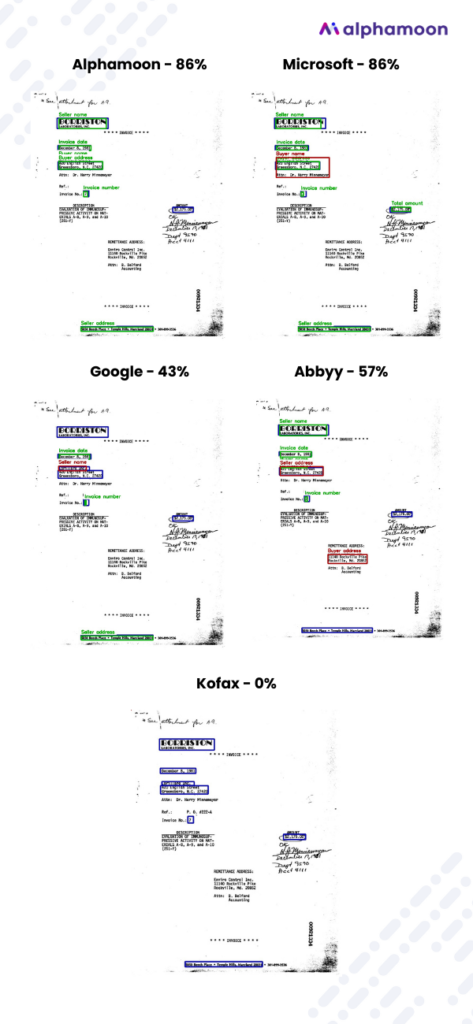
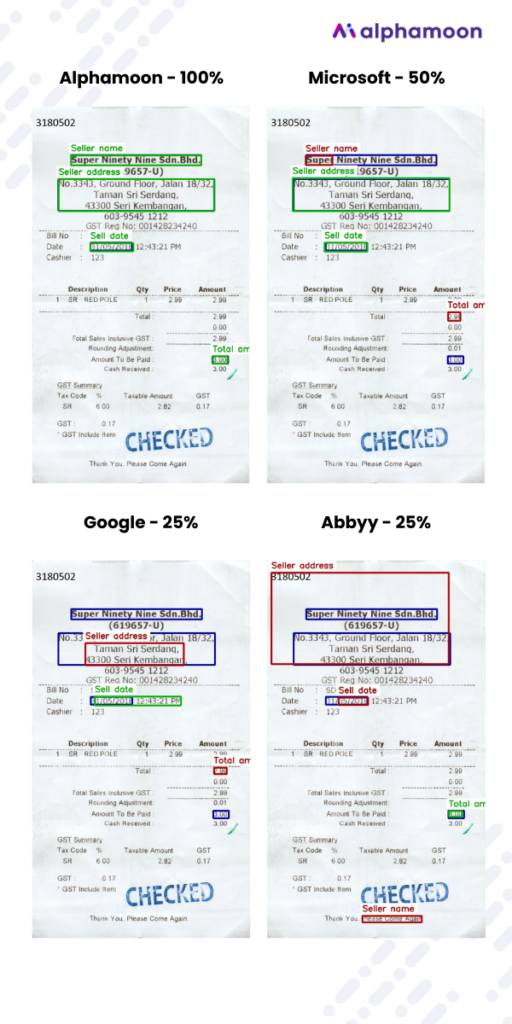
Below you can see a comparison of just one particular invoice and how all the tools managed to extract particular data pieces from it.
The green frames indicate the correctly extracted data – True Positives; red frames – False Positives; and purple ones – False Negatives.
The second metric we’ve used is Straight-Through Processing.
Alphamoon’s data extraction tool has successfully processed a full set of data fields from 36.7% of the whole set of invoices. In other words, 36.7% of invoices did not require any amendment or correction.
Microsoft and Google tools scored 8.5%, meanwhile, ABBYY and Kofax did not process any invoice from the dataset 100% accurately.
Conclusion?
Almost every single invoice processed by every other vendor than Alphamoon would require some degree of correction.
Let it be emphasized though, that this metric has less business significance than accuracy, however, it provides an insight into just how capable the given tool is in handling all data if human supervision wasn’t needed.

We’ve identified a few common errors and struggles during the detailed error analysis:
- Finding the right total amount to pay. Documents for payment contain many places where a certain amount of money is provided. A common mistake that platforms make is to mark the net amount instead of the gross amount.
- Sellers place logos and other graphics that often contain text. This confuses the model because that text might be mistaken for the “seller name” field. An additional difficulty is that the logo is a piece of design artistry, with non-standard fonts, lettering, and other shapes. Not the best set-up for rule-based tools.
- Invoices have their difficulty in the fact that they consist of many fields. Since there is no universal template for invoices, OCR platforms that are not supported by AI struggle with the more complex invoice designs.
Since the dataset was quite challenging, we have also tested Alphamoon against a more up-to-date dataset. Since the dataset was not publicly accessible, we did not run the test on any other vendor’s platform.
Below are examples of the invoices from that second dataset.

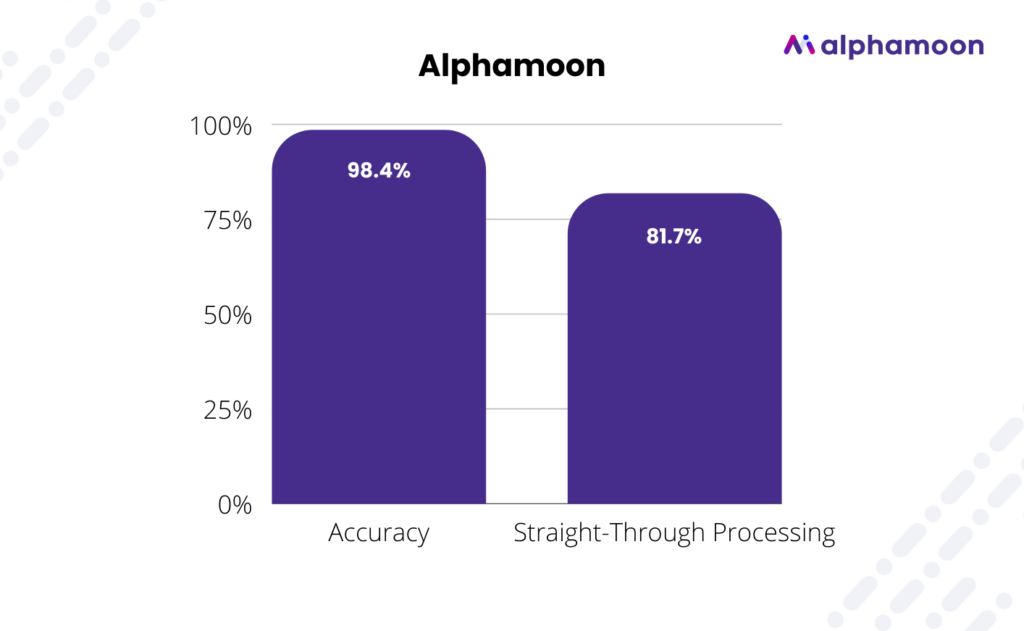
The internal dataset of modern invoices has yielded astonishing results. Alphamoon Invoices has achieved an accuracy of 98.4% and a Straight-Through Processing score of 81.7%.
What does it mean in business terms?
98% of accuracy means that information extraction is no longer your worry. Your team focuses on data modeling and knowledge processing, rather than manual tasks. Furthermore, the tool retrains and learns as you go, because the more invoices are processed, the more accurate the tool is. Alphamoon generates an ordered overview of all extracted fields, providing you with a better understanding of all the information stored in your documents.
In order to better portray the strengths of our platform, we have extrapolated data concerning particular fields extracted across all invoices.
The accuracy of all data field extractions ranged from 100% to 96.6%.

Summarising the comparison of Invoice data extraction, Alphamoon has topped each competitor in both metrics used in the evaluation – accuracy and Straight-Through Processing.
Below you can find an in-depth look at all the fields and how well each tool performed in terms of information extraction.
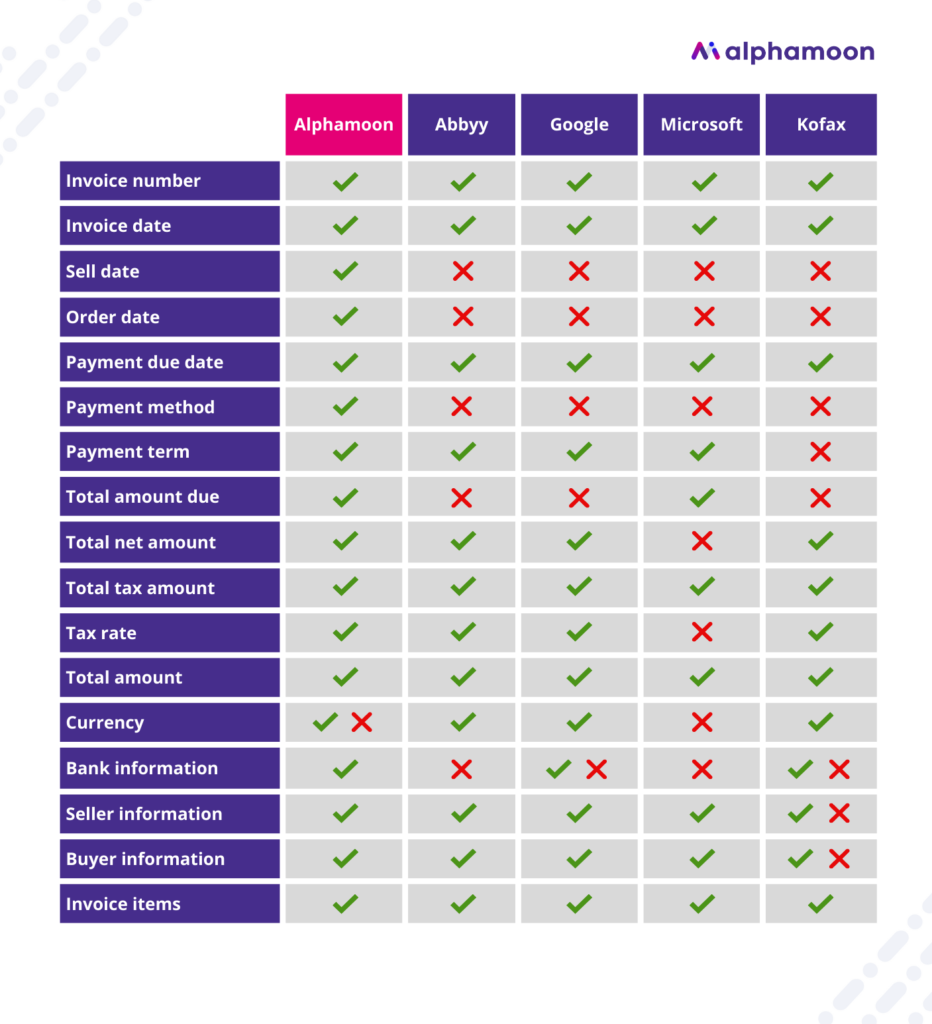
The above shows that Alphamoon provides the broadest range of particular data fields extraction. Thanks to the IDP technology, our tool learns with each set of invoices you need to process.
In other words, the more documents the AI OCR from Alphamoon processes, the better the fit.
If you’re looking for the top quality of automated invoices processing, get in touch with us now.

Data extraction from receipts – Comparison of Alphamoon, ABBYY, Google, and Microsoft
The second part of the comparison was conducted on a dataset consisting of 347 receipts.
The SROIE Dataset for receipts consists of different quality receipts and it serves ideally to check the accuracy of data extraction. On this dataset there are only four fields labeled: seller name, seller address, sell date, and gross amount. For this part of the test, we compared Alphamoon with the following tools:
- ABBYY Cloud OCR SDK for receipts
- Google Document AI Expense Parser
- Microsoft Azure Form Recognizer receipt model
Below is a set of 5 various receipts from the model.

The accuracy of Alphamoon in the receipts data extraction has once again proven to be the highest among the vendors.
Alphamoon has achieved 89.5% of accuracy, followed by Microsoft’s 87.8%. The performance of Google reached 68.3%, while ABBYY did not get more than half of the fields correctly.

Contrary to the dataset we’ve used in the invoices test, the receipts did not create a similar challenge. Although the receipts were outdated too, the sheer design of receipts is less prone to change and visual variation.
Judging by the second metric, Straight-Through Processing, Alphamoon has extracted 100% of data correctly from 62.2% of receipts. Next in line was Microsoft’s Azure Form Recognizer receipt model – 51.6% – then Google’s Document AI Expense Parser – 14.7%. ABBYY Cloud OCR SDK for receipts has once again taken the 4th position, with only 6.3%.
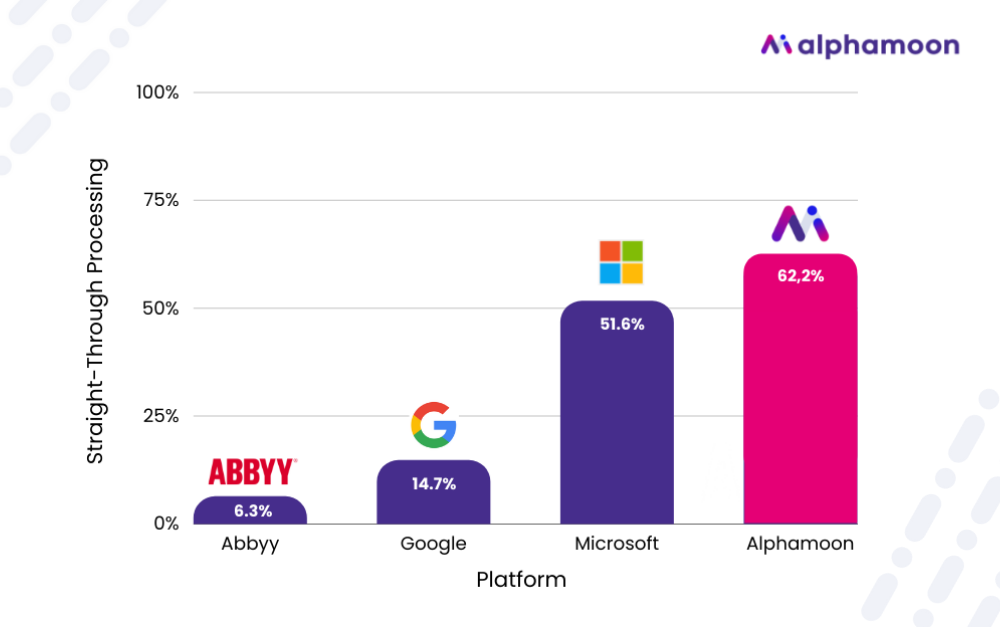
Let’s take a look at two examples of the same receipt and the data extraction accuracy score of all four vendors.
In the image below, ABBYY software clearly struggled with the wrong classification of a paper punch that the tool recognized as the Seller Name field.

The compilation below shows another difficulty for most of the tools – the various fields containing monetary values. A common mistake that the data extraction software makes is marking the net amount instead of the gross amount – as is the case of Microsoft and Google in the screenshot below.
What is the best data extraction software for processing invoices and receipts then?
To conclude:
- In both metrics, Alphamoon achieves higher results than the competitors. Based on the evaluation of accuracy and Straight-Through Processing, Alphamoon is the best OCR and data extraction software.
- Based on a challenging set of outdated templates of invoices (dictated by the public access), Alphamoon has achieved 82.5%. The 2nd score was 75.4% achieved by Microsoft.
- In an additional test of Alphamoon, conducted on an internal set of invoices, our tool has achieved a stunning 98% accuracy level.
- In a comparison of receipts, Alphamoon has achieved 89.5% of accuracy.
The high scores achieved by Alphamoon have direct business benefits that you can test in your business case too.
Alphamoon platform employs the Intelligent Document Processing technology, the best available method for document automation. IDP combines the joint power of NLP, AI, and ML – that is natural language processing, artificial intelligence, and machine learning – to provide you with the most capable automation of all document processing. The platform enables users to pre-process documents with document classification and tagging, extract data from them and store safely in the cloud.
Considering the 98% of data extraction accuracy that our platform achieved on a set of modern invoices, your accounting or finance team would only need to monitor the correctness of output, rather than dealing with all the manual work on their own. Such savings can be expressed in many ways too. Your team will smoothly move to more intellectual work, while your document processing will become more efficient and take less of your time.
So, the question is – are you ready to chat with us about your document automation?


