Zero-shot learning is a term that’s been causing a buzz lately. But why is that, and how does zero-shot work? Zero-shot learning is the ability of an AI system to recognize and respond to new situations that it hasn’t explicitly been trained on.
This concept may sound simple, but it is actually revolutionary in the world of AI.
Zero-shot learning method opens up exciting possibilities for tackling complex tasks that were previously difficult for machines to handle. With zero-shot learning, machines can now adapt and learn in ways that were never before possible.
In this article, you will discover how Zero-shot learning can:
- Revolutionize document processing
- Make your document data extraction faster
- Eliminate the frustrations associated with manually copying and pasting data from various documents.
What’s the Difference between a Supervised Model Training and Zero-shot Learning
Well, if you want a machine learning (ML) model to complete a task for you, say, extract data fields from a recent tax form you submitted to tax authorities, you have two options:
- Use traditional models that require a training phase
- Use an innovative zero-shot model that doesn’t require a training phase
Technically, you also have a third option: doing it manually. But we believe you, at this point, already believe that automation is the way to go.
So, curious what’s the difference between traditional model learning and zero-shot learning? Let’s jump right in.
Difference between Supervised Model Learning and Zero-shot Learning
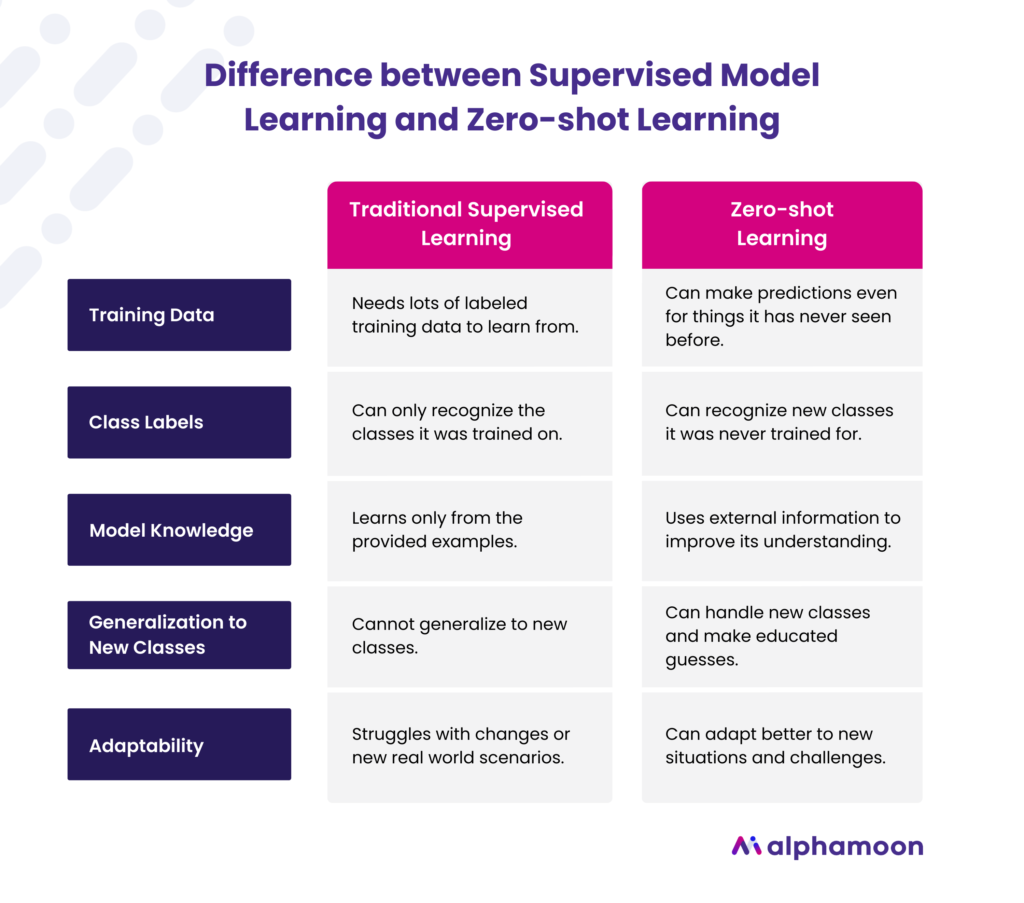
How Does Traditional Supervised Model Training Work?
So here’s the basic idea of how machine learning and deep learning models (DL) work right now.
There is a pre-trained model that’s a very large neural network. Say, it’s a deep network of transformers, as it’s the case in natural language processing (NLP).
And to train this model, a data engineer has to use some data sets in either unsupervised/self-supervised or fully supervised manner (or both).
Such a model must also be fine-tuned using a labeled training set containing a few hundred examples to work on your task. For example, to extract data from your invoice.
The issue here?
You have to prepare, clean, and label data. Oh, and one more thing — your data has to be diverse enough so the model’s performance is good and there is no bias in the output.
And yeah, you already guessed it — you won’t always have quality data or diverse datasets. As a result, the model’s capabilities to solve tasks may be limited.
And this is where the zero-shot model shines.
What Is Zero-Shot Model Definition and Capabilities?
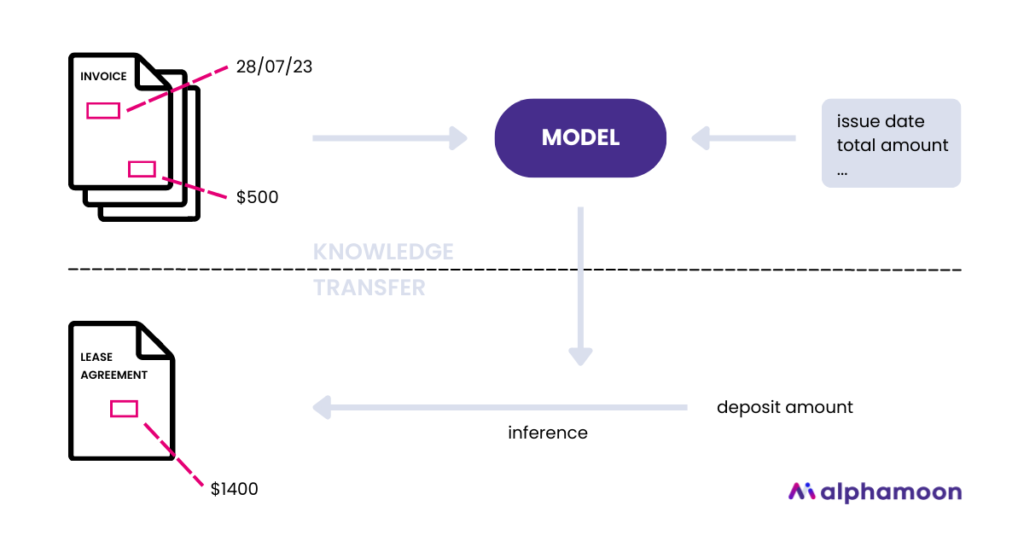
Zero-shot learning is a relatively novel approach to Machine Learning and data science where a model generalizes its knowledge to recognize and classify objects or concepts it has never seen before.
Unlike traditional learning methods requiring tons of labeled training data, zero-shot learning moves past that. It lets machines learn from textual descriptions or attributes associated with the classes they are meant to recognize.
Because of its capabilities, zero-shot learning has much potential in the following domains:
- Natural language processing, text, and image classification
- Recommender systems and personalization
- Computer vision and object recognition
- Robotics
This type of learning got super popular with the outburst of Large Language Models (LLMs) like ChatGPT, Falcon, LLaMA, or Dolly. LLMs have an excellent ability to generalize over (complete) tasks they have never seen before.
For example, a zero-shot learning model trained on different invoice types might be able to recognize a new invoice type (e.g., proforma invoice) it has never seen before based on its understanding of the attributes an invoice should have.
Sounds great, right?
Now, you won’t have to spend time (or wait for machine learning experts) to train and fine-tune the models. You just need to configure the intelligent document processing platform and start using it immediately for any use case you have.
It opens new possibilities and gives back power to you. Now, forget about pulling data from less popular documents manually and start using zero-shot.

Zero-Shot Learning: Benefits and Drawbacks
While zero-shot learning is a revolutionary approach in ML, it has advantages and limitations. Let’s discuss them.
Benefits of Zero-Shot Learning
Check the list of benefits that zero-shot learning holds:
- Expanded knowledge representation: Zero-shot learning allows machines to learn and understand new concepts without explicit training. It enables the platform to capture fields from any document without limitations on what data you can extract.
- Improved generalization: Zero-shot learning allows AI to learn without direct training on a particular task. In document data extraction, a model with prior knowledge of extracting names and dates can apply this knowledge to recognize and extract new types of information like addresses or phone numbers without additional training.
- Enhanced decision-making: By incorporating semantic relationships between classes, zero-shot models can make informed decisions even when faced with ambiguous or incomplete data. This ability to reason and infer is crucial in various real-world scenarios.
- Reduced data requirements: Unlike traditional machine learning methods, zero-shot models can make accurate predictions even with limited labeled data. It makes it particularly useful when data collection is time-consuming or costly.
- Efficient resource use: Zero-shot learning reduces the need for manual annotation or labeling of vast data. It saves time and effort, allowing organizations to allocate resources more effectively and focus on other critical tasks.
As you see, zero-shot learning unlocks many exciting possibilities for advancements in artificial intelligence. Thanks to this technology, you can get an intelligent processing tool capable of processing ANY document type.
But the world is no fairy tale, and zero-shot technology still has some challenges. Let’s take a look.
Challenges of Zero-shot Learning
Zero-shot learning has the following challenges:
- Limited data availability: Obtaining labeled examples for every possible concept becomes daunting in zero-shot learning scenarios. This scarcity of labeled data hinders the model’s ability to generalize and accurately classify new classes. As a result, developing robust Zero-shot learning models that can effectively learn from limited data remains a significant challenge.
- Requirement for substantial computational power: working in practice with a significant language model is challenging because you need many computational resources to deploy it.
- Limited in optimizing end-to-end processes: Zero-shot learning starts with 80% accuracy. There may need to be more to automate the end-to-end process fully. For the most accurate results, zero-shot should be combined with adaptive learning.
- Ambiguous and subjective: Another challenge in zero-shot learning arises from the inherent ambiguity and subjectivity in defining and describing unknown classes. Different individuals may have varying interpretations and perspectives regarding understanding concepts, making it challenging to establish a unified ground truth for training models.
At Alphamoon, our machine learning experts are continuously overcoming obstacles to advance zero-shot learning, aiming to develop models that can efficiently learn and identify unfamiliar ideas.
How Does Zero-Shot Learning Work with Documents?
LLMs zero-shot models are pre-trained. They use trillions of different documents where they learn to predict the next word in the sentence. It’s based on a very sophisticated compressing algorithm learning how to correlate different information in those documents.
Zero-shot and Document Data Extraction
Here’s how applying zero-shot learning in document extraction works.
By giving a new context to such a model, for example, by defining what should be extracted from the document, the model transfers knowledge already learned to perform the task.
For example, you want to extract the name and surname from a document. The model understands that those fields appear in some specific context in documents. To solve this particular task, it will use that knowledge to solve this particular task.
Zero-shot and Document Classification
You can also apply zero-shot learning to document classification. And it’s also about knowledge transfer.
Such models have already seen millions or billions of different documents. They probably know all the docs you’d like to classify.
Just by defining the document type, such a model already knows what this document should look like. It means what kind of phrases and semantics the document should contain. Based on that, our model can perform the zero-shot classification.
But that’s not all.
Zero-shot and Document Question Answering
There are two ways of document question-answering:
- Extractive: it means that you are asking to find specific information in the document
- Abstractive: it means that you are asking questions related to the document
4 Applications of Zero-Shot Learning in the Document Processing Field
Now, the most helpful part for you. How will zero-shot learning help you extract data from any document you wish?
1. Residential Lease Agreement Data Extraction
Real estate and property management industries can benefit from automated data extraction from various types of lease agreements.
To get your agreement processes, press “New process” to set up data extraction from your document. Watch this short video of how to create your first custom process.
It’s really that simple.
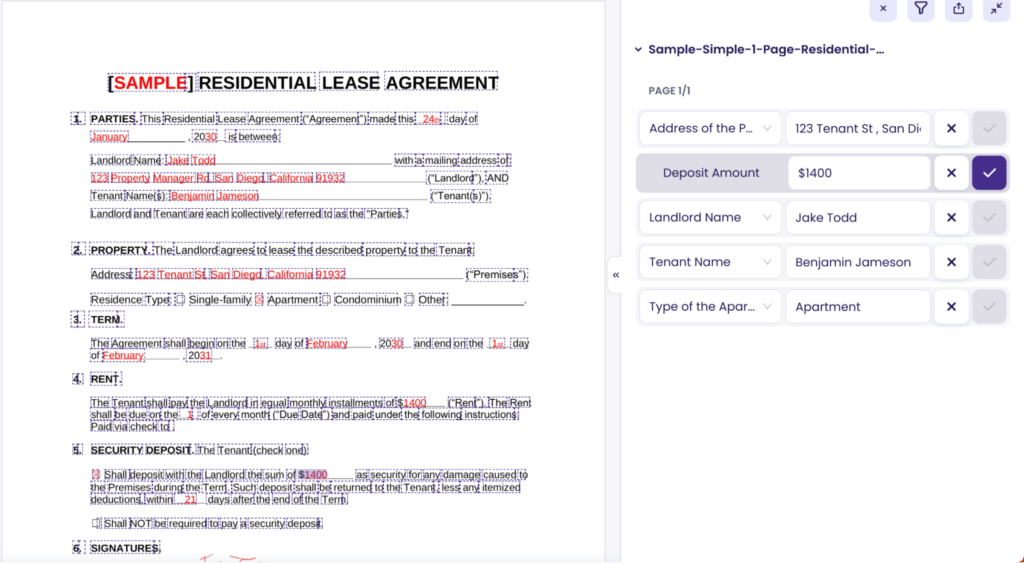
After the document has been processed, press it to see how the extraction went.

Most of the extracted fields are correct, like the property address, landlord name, tenant name, and type of residence.
There is one small mistake that you should correct, which is the deposit amount field. Technically the deposit amount equals $1400, but the tool should take the amount from the fifth section, not the fourth.
To correct it, just hover over the deposit amount window, press three dots on the right, “reassign words, ” and press the $1400 in the fifth section of the document.
Now let’s see how data extraction works for documents with a template in Alphamoon Workspace.
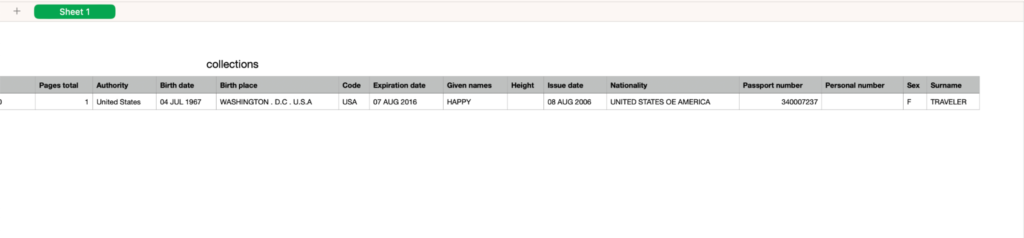
2. Passport Data Extraction
Automated passports and IDs data extraction can significantly improve efficiency, accuracy, and customer experience while ensuring compliance with regulations and security standards.
In this case, you can choose the “Passport” template, press “proceed” and “upload,” and wait for the passport to get processed.

It may happen that your document will have the status “Needs review”. Let’s check out what’s necessary to adjust there.
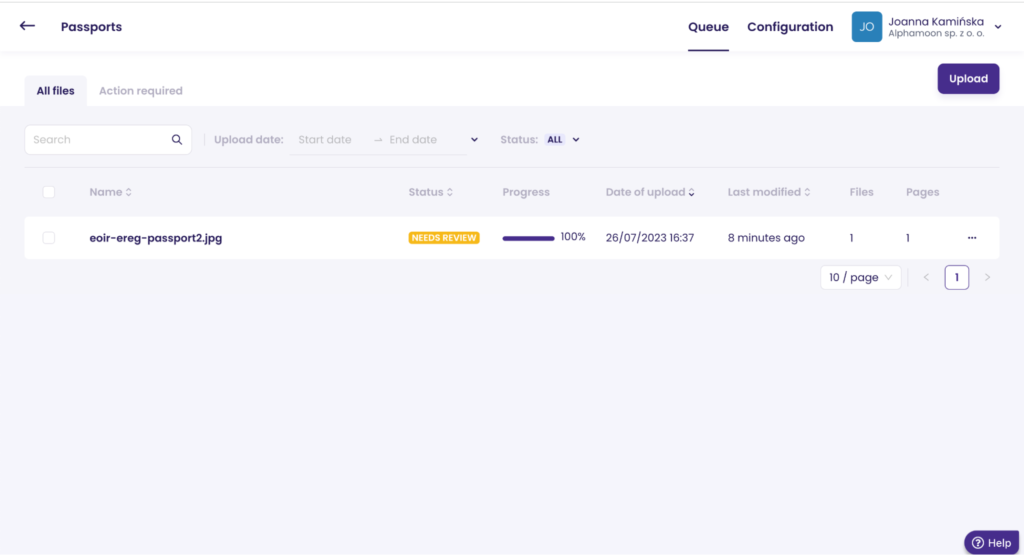
After a quick look, there is no personal number on this passport.

You can accept the document, as the rest of the data extraction went 100% well. After that, the status changed to “Accepted.”
3. Train Ticket Data Extraction
Extracting relevant information from train tickets can be challenging due to variations in formats and layouts.
However, zero-shot learning algorithms excel in handling such scenarios. It can recognize and extract essential details like departure and destination stations, date and time of travel, seat number, and ticket fare.
Just watch a short video of how data extraction works here.
Short demo of zero-shot video.
Zero-shot learning algorithms simplify ticket data extraction by leveraging their understanding of diverse ticket designs.
4. Tax Return Data Extraction
Zero-shot learning algorithms also prove to be invaluable when it comes to handling tax returns. It can analyze tax forms and extract essential details such as income, deductions, credits, and tax liabilities.
By understanding the structure and context of tax documents, zero-shot learning algorithms can accurately identify relevant information and streamline the tax return process for individuals and businesses.
This time, the document is in Spanish. We decided to extract the following information:
- Tipo de declaración (Type of declaration)
- Impuesto a cargo (Tax payable)
- Cantidad a cargo (Amount payable)

When you proceed to “Queue,” you’ll see how the data extraction went.

As you see, all the data was correctly extracted, even from a document in another language than English. That’s the power of zero-shot!
You can export document data in CSV, JSON, or Excel files. It can help you send data to other tools in your stack or analyze it.
Improve Your Document Processing with Zero-shot
As you see, zero-shot learning can remove document processing headaches from the equation.
With its ability to extract data from any document, you can process documents faster, with fewer errors. It lets you spend more time on strategic tasks than sinking into the pile of documents needing your attention.Try processing the first 50 documents for free: sign up to Alphamoon Workspace today!
FAQ:
What is zero-shot learning in NLP?
Zero-shot learning in NLP is an approach to machine learning where a model can generalize to unseen classes or tasks without direct training. Instead, it relies on learning relationships between seen and unseen classes during training. It involves inferring the correct output without explicit supervision.
What is the difference between zero-shot and one-shot?
The main difference between zero-shot and one-shot learning is that zero-shot learning deals with unseen classes, while one-shot learning deals with limited examples per new class. In one-shot learning, the model is provided with a single example for each new class during training.
What is zero vs few-shot learning?
In zero-shot, the model predicts unseen classes without training examples. At the same time, in a few-shot, it learns from limited examples per class.
Is zero-shot learning supervised or unsupervised learning?
Zero-shot learning is a form of supervised learning since it learns from labeled data during training, albeit not directly from data for the unseen classes.
What’s the role of semantic embeddings in zero-shot?
One of the critical components of zero-shot learning is using semantic embeddings. These embeddings are mathematical representations of objects or concepts in a continuous vector space. By mapping attributes and objects into this vector space, the algorithm can measure their semantic similarity.


