As your business grows, so does the number of documents that need to be categorized. While manual document classification is an option for low document volumes, you can’t afford to continue plowing through a massive pile of documents the same way.
Suppose you want to find relevant information quicker and make processing smoother. In that case, automated document classification based on machine learning can assist you.
In this article, you’ll learn more about document classification and its role in business. Find out where automatic document classification surpasses the manual process and how to start with the implementation.
Let’s get right to it.
What is Document Classification?
Document classification (document categorization) refers to recognizing a document category based on its content, visual appearance, and other factors.
You can classify documents into folders based on labels you create, for example:
- Level of confidentiality: public, confidential, top secret.
- Type of document: invoice, corrected invoice, receipt.
- Language: English, French, Spanish.
If you think about document processing in a bigger picture, document classification works as just one step in the bigger process. This is where it fits:

Importance of Document Classification
If you want to have a full control over your entire document processing workflow, you have to perform classification of all the documents. Especially when they come in large volumes.
Classification helps retrieve and access information and optimize document management process. As a result, employees make better-informed decisions and have quicker access to important data.
Another thing is that consistent document labels help your employees onboard new colleagues faster so they can find key documents in a snap.
Document text classification is crucial for one more reason – it helps you stay compliant with internal policies and external regulations.
Say you’d like to better adhere to internal policies and categorize documents based on their sensitivity level. Docs that contain personal information can be labelled “confidential” and stored in separate files that are accessible to a limited group of employees only.
Moreover, proper document data handling can also develop trust in your business relationships with customers, partners, or suppliers.

Now, let’s see different methods of document text classification.
2 Document Classification Methods: Manual vs. Automated
Ok, you have two options to assign relevant categories to your documents: manually or automatically. If you use a tool to classify documents automatically, you use either traditional machine learning models or modern technology based on deep learning and neural network.
Let’s dive into details.
Manual Data Classification
Manual data classification (as the name says) is done by a human who reads, understands and categorizes documents based on agreed rules.
In case of a couple of documents a month, the process seems pretty painless.
But if you have hundreds or thousands of documents that have to be classified each month, this becomes a huge problem. Think about it, you’ll spend a couple of minutes on every document because it needs to be found, analyzed, assigned to a category and pasted to the right location.
Challenges of Manual Document Classification
To classify big batches of documents, one of your employees will have to spend hours getting everything sorted out. In the case of interns or other inexperienced staff, it can take even longer.
And at the end of the day, there is no guarantee that your employees won’t mix up records and put documents into the wrong categories in your document classification system. Such mistakes can be costly, especially in industries like healthcare, where wrong document labels can impact treatment decisions or lead to personal patient data mishandling.
Sounds pretty bad, right?
But it’s not all – there are other obstacles along the way.
When employees digitize documents, they usually scan them first. A huge pile of multi-page documents (comprising hundreds or even thousands of pages) becomes one chunky PDF file. In many cases, scanned documents are low-quality, which slows down the whole process. Some free document processing tools can help split pages, but that’s often the end of the road. Labeling documents are still on your team’s task list.
Thus, manual classification of documents has a lot of cons because it’s:
- Time-consuming for your team.
- Prone to errors and inconsistencies.
- Impossible to scale when dealing with larger volumes of data.
Automatic Document Classification
Automation can solve issues with sluggish document classification so you can better allocate your time and resources.
In this case, you get your documents classified to the right categories automatically. All you have to do is to do a quick check afterwards if the machine learning algorithm assigned your docs to the relevant categories.
Sounds better, right?
Automatic data classification is more accurate, faster, scalable and less expensive compared to manual classification. Companies across finance, healthcare and legal are implementing this more optimized way to handle their documents.
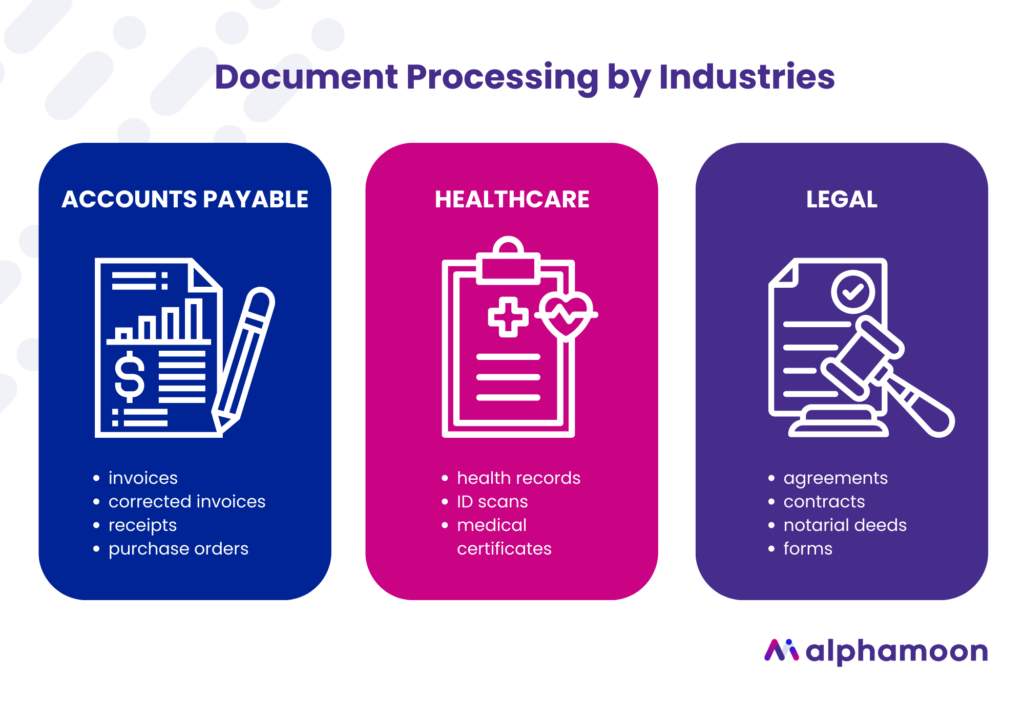
For example, Account Payable teams process, for the most part, invoices, corrected invoices, receipts, purchase orders, and other documents within the domain of transactional paperwork. Employees in the field of healthcare process personal records – medical certificates, health records, ID scans, etc.
These two separate groups do the same operations, including categorization, document data extraction, and paperwork archiving. However, document categories and the sort of documents used in their line of work differs.
Challenges of Traditional Automatic Document Classification
The task of recognizing document classes is time-consuming but relatively easy for humans. And it may seem to be a similarly easy-peasy job for robots. However, many legacy tools cannot do document recognition with high precision.
Here’s why.
Visual appearance, content, or layout may vary among documents in the same category. From the programming perspective, preparing code to handle any specific document type is intractable.
Furthermore, the number of categories may be significant and vary over time whenever business processes change due to internal or external reasons.
As the range of document classes grows, traditional automation models may have difficulty determining the differences.
The issue deepens when types may be very similar regarding document appearance and content (e.g., invoice and corrective invoice), confusing even for humans. So, whenever the order of classification changes, the software needs to be agile and adaptable.

Another issue is that documents may be long too and contain much text and other components like tables and images based on which the classification has to be performed, and this is challenging from the processing point of view.
Finally, traditional platforms struggle when the quality of scanned documents is poor. As a result, it is particularly difficult for legacy Optical Character Recognition (OCR) software, which turns images into text.

In general, traditional automated document classification is useful, but as you see, it has its limitations. But there are newer techniques that take those limitations out of the equation and improve the accuracy of your document classification. Let’s get into them.
Modern Automatic Document Classification Techniques
There are various automated document classification techniques that have emerged over the past years. Today, modern intelligent document processing tools combine several machine learning techniques like NLP (natural language processing) and computer vision.
What’s important here is that today’s models are more advanced and because of their complexity, they can better recognize word combinations that help them understand the context of the document better.
Let’s see what they are and how modern OCR and document scanning tools use them.
Computer Vision Recognition Based on Machine Learning
Computer vision mimics the human ability to see things. Since algorithms can’t take a glance at a paper and determine its type like humans, machine learning engineers came up with ways to teach AI models to translate images into non-abstract entities. Computer vision techniques analyze documents as images and learn distinctive visual features. Because of this, they work best on files with distinctive document structures like IDs, passports, driver’s licenses, etc.
Textual Recognition Based on Natural Language Processing (NLP)
Another technique you can employ is a subset of machine learning called natural language processing (NLP). In NLP algorithms, understand the text content of a document by analyzing all the words, phrases, and the whole structure of the text. Thanks to this analysis, they assign the document meaning and a relevant category to docs.
NLP works great with documents with much-unstructured data like emails, contracts, notarial deeds, or resumes.
How Modern IDP Tools Use Deep Learning Techniques
A modern IDP tool should use use technology based on deep neural networks for document classification.
For example, in Alphamoon, we use a multimodal deep learning neural network that can handle three different modalities:
- Textual context and semantically similar words.
- Position and size of the words.
- Visual appearance of the document.
This approach is similar to how humans look when they are determining the category of documents. The key difference is that robots do it way faster.

Now, let’s get more technical.
Multimodal deep learning models are very effective in document classification and achieve outstanding results – usually over 95% accuracy on average.
AI-based classification models can also be easily applied to different document classification tasks (by a different task, we mean a different set of category labels).
These models are taught by data scientists who use so-called transfer learning, which works as follows:
- Reuse machine learning model: They use a pre-trained model that serves as the starting point for a model for document classification. For the task of document classification, they can use unsupervised document classification or self-supervised ways to pre-train the model.
- Tune the model: Supervised document classification or semi-supervised classification helps engineers fine-tune the model already on a specific document classification task.
Every method needs a proper input data and training data preparation.
Alphamoon’s classification algorithm tackles most of the common challenges we’ve explained earlier:
- The model can deal with long documents by using a unique structure of network components.
- By using different modalities, Alphamoon can partially handle the problem of low-quality documents and documents that contain objects like tables and images. This includes recognizing invoices and corrected invoices.
- Our engine handles a large number of different categories and adapts to new classes and new document types by using dedicated continual learning classification algorithm.
- Continual learning as part of the model leads to improved document classification accuracy over time, thanks to new training dataset examples. This helps in future cases of distinguishing similar categories of documents and tackling the problem of an unknown/unseen sort by using a particular type of loss function for training the model.
As a result, you can categorize more documents in a shorter time, improving your business efficiency.
Benefits of Using Automated Document Classification
Several benefits come from investing in classifying documents in a modern way, including:
- Increased efficiency: It helps your business save time and reduce errors by quickly and accurately classifying documents.
- Better organization: It helps your business better organize documents, making it easier to find relevant information.
- Improved accuracy: It reduces the risk of errors and helps you stay compliant with regulations.
- Reduced costs: It helps your business save money by reducing the need to classify documents manually.
- Enhanced security: It helps your businesses protect sensitive information by ensuring that it is properly categorized and stored.
As you see, automated classification is a powerful way to improve your business processes, no matter what industry you’re in. Think about the IDP tool as an assistant that helps you do the job and lets you verify the outcomes in the core moments. Thanks to keeping humans in the loop, you’re always sure the results are correct.

Classify Documents in Your Business in a More Efficient Way
Thanks to modern AI-backed tool automatic document classification helps your team assort documents faster.
Look for those traits when choosing your next document classification tool:
- Quick & easy deployment. For example, our team can help you onboard so that you can reap the benefits of intelligent document processing fast.
- Intuitive UI. Your document classification took should be easy to use for those who don’t have coding skills.
- Easy to integrate with your stack. Data classification is one but it’s just a part of a bigger process. Your IDP tool should connect with Google Drive, OneDrive or with thousands of other apps via Zapier.
- Has a continual learning component. The feature of continual learning guarantees that the model learns as it goes, hence providing improved accuracy that is specific to your use cases.
- Goes with complementary document management. Your tool should let you do Optical Character Recognition data extraction and full-text search so you can improve the whole process, not just the categorization alone.
As the demand for automated document classification grows, the sooner you test out the IDP tool, the better. Try out Alphamoon and start transforming your document management process and unlock the full potential of data from your documents.


